Enterprise Data Warehouse Architecture | Oracle Enterprise Data Warehouse

What is an Enterprise Data Warehouse?
An Enterprise Data Warehouse (EDW) is a form of corporate repository that stores and manages all the historical business data of an enterprise. The information usually comes from different systems like ERPs, CRMs, physical recordings, and other flat files. To prepare data for further analysis, it must be placed in a single storage facility. This way, different business units can query it and analyze information from multiple angles.
Enterprise Data Warehouse Architecture
While there are many architectural approaches that extend warehouse capabilities in one way or another, we will focus on the most essential ones. Without diving into too much technical detail, the whole data pipeline can be divided into three layers:
- Raw data layer (data sources)
- Warehouse and its ecosystem
- User interface (analytical tools)
The tooling that concerns data Extraction, Transformation, and Loading into a warehouse is a separate category of tools known as ETL. Also, under the ETL umbrella, data integration tools perform manipulations with data before it’s placed in a warehouse. These tools operate between a raw data layer and a warehouse.
When the data is loaded into a warehouse, it can also be transformed. So, the warehouse will require certain functionality for cleaning/standardization/dimensionalization. These and other factors will determine architecture complexity. We will look at the EDW architecture from the standpoint of growing organizational needs.
One-tier architecture
Given that data integration is well-configured, we can choose our data warehouse. In most cases, a data warehouse is a relational database with modules to allow multidimensional data, or one that can separate some domain-specific information for easier access. In its most primitive form, warehousing can have just one-tier architecture.
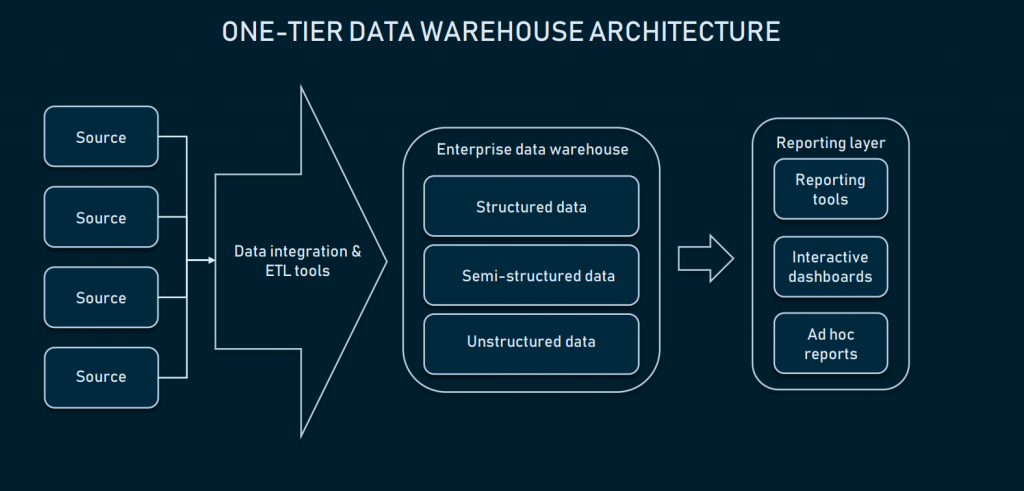
One-tier architecture for EDW means that you have a database directly connected with the analytical interfaces where the end user can make queries. Setting the direct connection between an EDW and analytical tools brings several challenges:
- Traditionally, you can consider your storage a warehouse starting from 100GB of data. Working with it directly may result in messy query results, as well as low processing speed.
- Querying data right from the DW may require precise input, so that the system will be able to filter out non-required data. Which makes dealing with presentation tools a little difficult.
- Limited flexibility/analytical capabilities exist.
Additionally, the one-tier architecture sets some limits to reporting complexity. Such an approach is rarely used for large-scale data platforms, because of its slowness and unpredictability. To perform advanced data queries, a warehouse can be extended with low-level instances that make access to data easier.
Two-tier architecture (data mart layer)
In two-tier architecture, a data mart level is added between the user interface and EDW. A data mart is a low-level repository that contains domain-specific information. Simply put, it’s another, smaller-sized database that extends EDW with dedicated information for your sales/operational departments, marketing, etc.

Creating data mart layer will require additional resources to establish hardware and integrate those databases with the rest of the data platform. But, such an approach solves the problem with querying: Each department will access required data more easily because a given mart will contain only domain-specific information. In addition, data marts will limit the access to data for end users, making EDW more secure.
Three-tier architecture (Online analytical processing)
On top of the data mart layer, enterprises also use online analytical processing (OLAP) cubes. An OLAP cube is a specific type of database that represents data from multiple dimensions. While relational databases represent data in just two dimensions (think of Excel or Google Sheets), OLAP allows you to compile data in multiple dimensions and move between dimensions.

So, as you can see, a cube adds dimensions to the data. You may think of it as multiple Excel tables combined with each other. The front of the cube is the usual two-dimensional table, where region (Africa, Asia, etc.) is specified vertically, while sales numbers and dates are written horizontally. The magic begins when we look at the upper facet of the cube, where sales are segmented by routes and the bottom specifies time-period. That’s known as multidimensional data.
